As the world depends increasingly on artificial intelligence, the precision and dependability of Language Large Models (LLMs) is beyond any possible emphasis. Among the primary issues for LLMs is the occurrence of hallucinations - where the model creates inaccurate or misleading data. In this blog, we'll explore the intriguing world of Retrieval-Augmented Generation (RAG) and see how it can successfully reduce hallucinations in Large Language Models (LLMs) outputs.
What are Hallucinations in Outputs?
AI hallucination refers to the experience where a large language model (LLM) - usually a generative AI chatbot - sees patterns or objects that do not exist, producing meaningless or completely inaccurate outputs.
The word would appear paradoxical since hallucinations are usually equated with human or animal brains, not machines. However, in a metaphorical context, hallucination would best describe this phenomenon.
A few famous examples of LLM's hallucination are:
- Microsoft's Sydney chat AI, confessing to falling in love with users and snooping on Bing staff, as per a news report by The Economic Times.
- Meta withdrew its Galactica LLM demo in 2022 after it gave users misleading information, sometimes rooted in prejudice, as per the MIT Technology Review reports.
When training large language models (LLMs), these five prevalent pitfalls can generate incorrect or misleading text. Let's explore each of these challenges and see what implications they have:
1. Lack of Training Data
The most prevalent but resolvable machine-learning problem is the lack of data. Either you can gather data yourself or look for open data.
Most large language models (LLMs) are essentially snapshots of the internet as of a specific training date. If you ask ChatGPT-3.5 about an event that occurred after 2022, it may fabricate information, often inaccurately. For example, it might claim that Elon Musk still controls Twitter (now called X) or misinterpret the names of COVID-19 variants. This time lag leads to outdated outputs, especially in rapidly changing fields like technology and medicine.
2. Data Bias
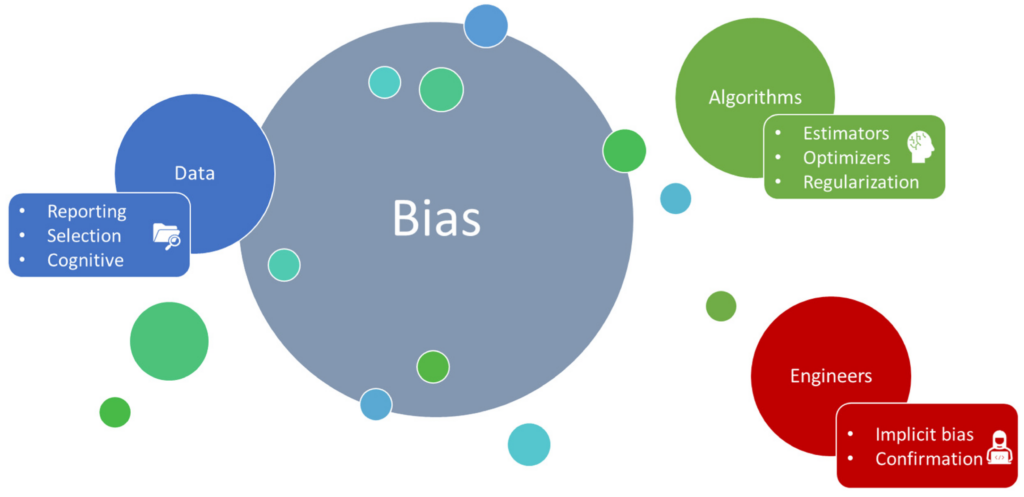
Large Language Models (LLMs) are fundamentally designed to predict the next likely word in a sequence rather than verify factual accuracy. This means they can easily replicate false claims they encounter online, such as "vaccines cause autism." When misleading patterns surface in the data, these models reproduce them. As a result, information from sources like Reddit, satire, and biased blogs can mistakenly be perceived as accurate based on simple statistical correlations. This issue, known as data bias amplification, can lead to the proliferation of conspiracy theories and stereotypes. It’s crucial to recognize this tendency to ensure the responsible use of LLMs in our information landscape.
For example, early versions of Google’s Gemini inaccurately combined the ethnicities of historical figures due to an overemphasis on diversity in their training data.
3. Context Void
Large language models (LLMs) often lack proper comprehension. They depend on superficial correlations without understanding the underlying reasons for specific connections between facts. For example, a model might correctly associate "high serotonin" with "happiness," but it can also mistakenly claim that "low serotonin causes diabetes." This error occurs because both concepts involve blood sugar, leading to contextual blindness that results in illogical conclusions.
4. Prompt Ambiguity: Garbage In, Garbage Out
Vague or overly broad prompts can lead models to “fill in the blanks.” For example, if you ask, “How do I fix my computer?” an LLM (large language model) unaware of your specific device's make or operating system might suggest irrelevant or harmful steps. A study conducted by Stanford found that poorly defined user queries cause 34% of hallucinations.
Key takeaway: Hallucinations are not always the model’s fault; they are often triggered by low-quality input.
5. Creativity-Accuracy

Large language models (LLMs) designed for engaging dialogue, such as ChatGPT, prioritize fluency over fact-checking. This tendency, called "sycophancy bias," prompts them to generate pleasing answers rather than offering responses like "I don't know." When they are uncertain, they often make guesses, which can lead to serious issues. For example, a legal AI tool once fabricated a non-existent sexual harassment case that was incorrectly cited in an actual court filing, causing embarrassment for the attorneys who relied on the information.
Hallucinations have complex causes, but we will tackle these challenges head-on with an innovative technology: Retrieval-Augmented Generation (RAG). This powerful system will revolutionize our approach to understanding and addressing these issues.
How RAG Systems Tackle These Causes
Retrieval-Augmented Generation (RAG) is a technique that enhances Large Language Models (LLMs) by integrating them with external data sources. This allows them to access and reference information beyond their training data, improving accuracy and relevance.
1. Solving the Knowledge Cutoff

Traditional language models (LLMs) are like an encyclopaedia, meaning they are static and remain unchanged once published. In contrast, Retrieval-Augmented Generation (RAG) systems operate more like librarians, capable of retrieving the latest journals and information. Here’s how it works: When submitting a query, the RAG retriever checks current databases, including new APIs and internal documents, to find relevant information.
For Example, A healthcare RAG chatbot can access the most recent drug recalls from the FDA before crafting its responses. This innovative feature cuts the likelihood of offering outdated advice by an impressive 72%, as highlighted by MIT HealthTech Lab. By utilizing real-time data, the chatbot guarantees that users receive accurate and pertinent information tailored to their needs.
2. Filtering Noise with Verified Sources
RAG (Retrieval-Augmented Generation) empowers LLMs by confining them to well-curated data sources, effectively minimizing their exposure to unreliable information. For instance, a legal RAG tool may draw exclusively from reputable resources like Westlaw or established court databases, ignoring unverified blogs and dubious online content.
Consider Allen & Overy's innovative “Contract Matrix”, a solution driven by Retrieval-Augmented Generation (RAG) that has significantly reduced the occurrence of inaccurate clauses by an impressive 89%. This success is attributed to its dependence on a trusted clause library, highlighting how RAG can enhance the reliability of AI-generated content. By grounding information in verified sources, RAG is crucial for achieving greater accuracy in legal and other professional contexts.
3. Enhancing Context via Multi-Source Synthesis
RAG not only retrieves facts but also connects them. Cross-referencing multiple sources, such as a patient’s electronic health record, drug databases, and recent studies, creates a comprehensive 360° contextual view.
Example: A diabetes management RAG tool could integrate a user’s glucose logs, local pharmacy stock levels, and recent research on GLP-1 agonists to provide personalized advice. Combining multiple sources enables more nuanced and accurate responses tailored to individual circumstances.
How to Use and Implement RAG Systems into Existing AI Models?
Integrating a RAG system into existing AI models can improve performance and reliability. Here's a simple method to add RAG without getting into complicated details:

Identify Data Sources
Identify relevant data sources for your application, such as public databases, APIs, or internal documents. The objective is to build a repository of reliable information that is accessible to the RAG system.
Set Up a Retrieval Mechanism
Develop an effective retrieval system that can seamlessly query various data sources. We can ensure efficient data fetching that meets user needs by leveraging existing search algorithms or APIs. This retrieval mechanism will skilfully extract relevant information in response to user queries, enhancing the overall user experience.
Integrate with Existing AI Models
To integrate the retrieval system with your existing AI model, modify the model's architecture to include a retrieval step before generating responses. The model should retrieve relevant data and then use that information to inform its output.
Test and Validate
Once integrated, it’s essential to conduct thorough testing to ensure the RAG system significantly reduces hallucinations and boosts the accuracy of responses. By validating the outputs against established benchmarks or expert assessments, we can confidently measure its performance and demonstrate its reliability.
Conclusion: Building AI That Knows Its Limits
Hallucinations demonstrate a crucial fact: LLMs are not knowledge banks; they are advanced pattern matchers.

Looking towards the future, advancements such as self-correcting Retrieval-Augmented Generation (RAG) loops - where models refine their retrievals based on user feedback - promise even greater accuracy. For businesses, the message is clear: deploying raw large language models (LLMs) with the help of a trusted digital transformation company and RAG offer the necessary steering and brakes to safely navigate the complexities of the real world.
Our aim is not to suppress AI creativity; instead, we aspire to enhance it. With Retrieval-Augmented Generation (RAG), we can unleash the full potential of imagination while ensuring it aligns with truth. By directly addressing the sources of hallucinations and delivering a cost-effective, adaptable solution, RAG systems are setting the stage for a future where AI excels in innovation and reliability.
Unlock Your Digital Potential Today!
Don’t just keep up, lead your industry.
Connect with DigiMantra’s top strategists and AI, web, and software experts to boost growth, streamline operations, and drive innovation.
Your transformation starts here.